Lesson from Support - The Most Common Causes of OpenVMS Network Disconnects

As I look back on my journey as a support specialist, I remember fondly those first few calls. I knew the answer to exactly one question. There were many calls on this issue, so it was a great place to start! Some of you can recall the days when we answered questions via the phone and not via email. Those calls opened the door to so many “by the way” or “while I have you on the phone” questions. Back in the day, those words struck terror into my heart. Nowadays, not only are most calls worked by email, but the one call that I could actually answer when I first started has disappeared. I don’t even train the new hires how to work that issue! Although, between us – I get a giggle whenever I see them taking their first calls. It brings back so many memories!
Today we will talk about a question/circumstance that has come up many, many times over the years: network disconnects (on the TCP/IP protocol). Customers call and say to me, “VMS is dropping me.” Or they say, “My network person says that VMS is causing disconnects.” Let me rip the bandage off right now. This will hurt some of you – or maybe it will hurt your network people. In TCP/IP Services for OpenVMS, we have no mechanism that will generate a spurious disconnect. There, I said it. If you are getting disconnected in a random fashion, OpenVMS did not do it! OpenVMS is a passive citizen on a much larger network. It plays well with others. So, let's explore some of the things that will cause this problem.
- Duplicate MAC address
I know that I just said that OpenVMS won’t disconnect you and it plays nice with others, but there is this one little exception. (This is actually system manager induced, so I feel like OpenVMS is still the victim!) Perhaps the simplest cause of disconnects would be a duplicate MAC address. For those of you that do not know what a MAC address is, in simple terms, it’s a 12-digit hexadecimal number that makes each NIC unique on a network. It is this address that allows every NIC to talk to other NICs on ethernet. Well, at least that’s the intent. Each NIC is assigned a MAC address at manufacture time.
Wait, if each NIC has its own MAC, how do you get a duplicate? Well, it is also possible for software to supersede that built-in MAC address at runtime. If you are running DECnet Phase IV on a NIC, you will get a new/modified MAC address that can be translated back to the DECnet address. As a matter of fact, LAT also has that functionality. It is happy to place the DECnet address on a NIC. We recently had a call like this. You see, DECnet will do a quick little test for a duplicate MAC and will throw an error on startup if it finds something in the LAN already running with its MAC address. But, if you did not start up DECnet, but started LAT, LAT could configure that MAC address onto that NIC. Most people don’t use LAT anymore – they don’t even realize that they have it running. But, when TCPIP starts up on that duplicate MAC, you will run into trouble sooner or later.
Let’s take a closer look at the duplicate MAC address. What is the manifestation of that? Well, you think you are connecting to HOSTA at 10.10.10.10, but, really, you got connected to HOSTB (IP address of 10.10.10.11). What? HOSTA and HOSTB don’t even have the same IP address! Well, if you look in the ARP table you could see that both of those addresses have the same MAC.
There was another call I took once. This call is more anecdotal than anything, but it happened. I was working with a customer once who had the technology to burn the MAC into their NIC cards. They had decided to use the same MAC for every card. They swore to me that they never had this issue before. They put a new NIC into one of the machines with the issue (it had a different MAC address) and the issue went away. The only way that their plan to burn the same MAC into every NIC would work would be if they never put two of those network cards into the same network.
Just a note – if you are running DECnet and it detects a duplicate MAC, DECnet will deliver OPCOM messages about the condition. We have seen customer ignore these messages.
- Duplicate IP address
Yes, people will place the same IP address onto multiple machines. How does this happen? Well, in most of these calls, the offender was on a PC. The person’s PC was “visiting” the LAN in question. They just picked a random IP address to place on their laptop. Some of you are shaking your heads wondering what would possess a person to just pick some random IP address – usually without even a check to see if something already owns that address!
How do we recognize this symptom? Well, perhaps you connected just fine to your OpenVMS system. Then, some minutes later, you are typing away and wham-o, you are not connected. You will see some sort of message about the remote side closing the logical link. When you go to connect again, you may get connected right up. On the other hand, you may not get connected for several minutes. And then all works well again until wham-o, disconnected again. How does that happen?

There is this table on every TCP/IP stack called the ARP (address resolution protocol) table. In this table is stored the IP address to MAC translation. Generally, when a machine comes on the network, or even when a new address is assigned to a NIC, a gratuitous ARP is sent out. It lets the local network know that IP address n.n.n.n is available on MAC nn-nn-nn-nn-nn-nn. The TCP/IP stacks on the network may cache that information. If information was already in their table, it would be flushed and replaced. Alternatively, there is an ARP kill timer. When that expires, the TCP/IP stack will poll the network and ask for translation of IP to MAC via the ARP protocol – “Who has x.x.x.x?” The machine that answers first will have their information cached into the ARP table. If another machine also answers, then the first entry is removed and the new information is cached. At some point, this table will be populated with the errant machine’s information and then disconnects will happen. The disconnect itself is caused by the peer system rejecting packets for connections that it doesn’t know about. If that system is rebooted or the network is shutdown and restarted, it will have a fresh set of network context with no connections active. Sending a packet for a connection that isn’t active results in the system responding with an RST packet (that is, a RESET packet).
You ask – does this actually happen today? You betcha! Look at our VSI support lab as a case study. We have multiple new system managers firing up test systems for learning purposes every week. These people are new to OpenVMS. Instead of teaching them to check out their own IP address when they create a NEW VM, I have been teaching them to run a quick ping check to see if anything is operating on what is about to become your new IP address. Of course, someone could have been using that IP address on a machine that is not currently running in that network. When that machine is back online, there will be issues. Are you thinking I should stop this bad behavior? Well, part of me is thinking that I should teach better habits. And the other part of me considers this a learning opportunity. Right now the learning opportunity is winning. (But I do have plans to change this!)
Consider another common practice: keeping copies of virtual machines around. These are so easy to start and stop that oftentimes their correct management is overlooked. If these machines are configured with a static address, then every time you boot that machine, or another copy of it, up comes that static IP address.
- IDLE connection killed
The symptom for this issue is simply that you walked away and came back and your terminal is no longer connected. You may or may not get an error. For me, recently, the symptom has been a dead terminal. This is to say that you can <CR> as many times and as vigorously as you would like – no one is home here.
This issue is caused because there is a network device between your local terminal emulator and the OpenVMS system which has detected that no traffic has been passed along that socket for some period of time. It decides that the connection is dead. It severs the connection. It may or may not notify the remote sides that a termination happened.
How do you prevent this issue? You play with your keepalive parameters. This can be done on the OpenVMS side or it can be done on the terminal emulation client. Either answer is perfectly acceptable. If multiple people are having this issue, it could make sense to adjust these parameters on the OpenVMS server. If only one person is having this issue, it could make sense to adjust their emulator.
Let’s back up and discuss the original purpose of keepalive. Keepalive was designed as a mechanism which can be used to probe idle connections. If the remote side of the connection answers, then all’s well and another probe will be sent later. If there is no answer from the remote side after a few attempts, then the socket is reset, and the system will free up the resources.
First, let’s talk about the keepalive parameters. Here is the output of the keepalive parameters on OpenVMS.
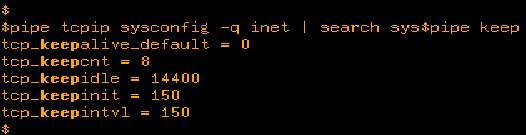
These parameters and how they work are documented in the TCP/IP Tuning and Troubleshooting Guide.
In short, if keepalive is turned on for a socket, then when the keepidle time is reached (that’s in half seconds), a probe is sent to see if the remote side is still around. If there is a positive answer, then the keepalive timer is set for another keepidle amount of time and the process repeats for the duration of the connection. If there is a negative answer, the connection will be dropped and reported immediately. (Such is the case where the remote host has rebooted without detection since the last keepalive probe.)
If there is no answer to that probe, then the keepcnt number of probes will be sent at time intervals regulated by keepintvl. If, at the end of all of that there is still no answer, then a reset is sent to the remote side and the OpenVMS side will close up the connection on its side.
The best case I have ever found to explain the need for keepalive revolves around my dog, Barney. Barney was a large golden retriever. He used to like to sit under my desk. Back in those days, we did not work from laptops. We did not have battery backup. So, I would be logged into a remote OpenVMS system, working away. Barney liked to sleep under my desk. Every once in a while, Barney would manage to lay on my power bar. He would toggle the power switch to off. Lights out, people. I was no longer connected – well, my PC was completely shut down. After power was restored and I rebooted, I could reconnect, no problem. But, lets look at the OpenVMS side. As far as the OpenVMS side knew, I was still out there. Maybe I went to lunch. So, whenever the keepidle timer went off, a probe was sent out. This probe went unanswered. It sent several others. All, unanswered. OpenVMS then correctly presumed that my session was a lost cause. It shut down my socket and returned all of those system resources back to the system.

The above story is an explanation of the original reason we had keepalive. Now, it is used to keep those idle connections from being killed by a network device between the 2 end points. What you need to figure out is how long a connection can remain idle before that system in the middle detects that idle connection and kills it. Unless you know your network people and they have the answer, this is done by trial and error. The default keepidle time is 2 hours (14400 half seconds). You would want to systematically lower that number until you find your sweet spot. If you have questions on how to do that, again, please contact support or you can find this information in the TCP/IP Tuning and Troubleshooting Guide.
- Random network issue
Once we have ruled out the first 3 issues, we are left with option number 4 – we had a random network issue. If you find that you have a lot of these, you will want to do something about it. If you call support, we will check to see if the situations described in sections 1 through 3 apply to you. Then, if not, then we will start to narrow down the issue. When looking at these things, it always seems like a good idea to see if either end of the connection was the cause of the problem. To do this, you would want to run a protocol trace on both ends of the connection. (TCPdump information may be found here.) These traces will be done at the same time, on the same connection. Then, when you have these traces in hand, you can see if either side generated the disconnect. If so, you know where to start your investigation. Most often I have found that the end nodes both receive disconnects or resets at the same time. Of course, if you were to look at the trace from 1 side, it would appear that the issue is on the other node. But when you look at the trace from the other side, you can see that the other side did not generate a disconnect. Instead, it also received one! The reality is that there is a device in between the two end nodes that is sensing an issue and sending both parties a disconnect. Once that is determined, the issue would need to be referred to the local network team.
Alright, those are the major causes of random or not so random disconnects experienced when dealing with TCP/IP Services on OpenVMS. Figuring out the cause of the problem is sometimes a bit of a journey. The good news is that I have never seen one of these issues that did not get explained before. Happy Networking!
Tech Support Manager

